Learning to Move Before Learning to Do: Task-Agnostic Pretraining for VLAs
Abstract
Vision-Language-Action (VLA) models are fundamentally bottlenecked by the scarcity of expert demonstrations—triplets of observations, instructions, and actions that are costly to collect at scale. We argue that this bottleneck stems from conflating two distinct learning objectives: acquiring physical competence (how to move) and acquiring semantic alignment (what to do). Crucially, only the latter requires language supervision. Building on this Decomposition Hypothesis, we propose Task-Agnostic Pretraining (TAP), a two-stage framework that first learns transferable motor priors from cheap, unlabeled interaction data—including discarded off-task trajectories and autonomous robot play—via a self-supervised Inverse Dynamics objective. A lightweight second stage then grounds these priors in language using minimal expert data. On the SIMPLER benchmark, TAP matches models trained on over 1M expert trajectories while using orders of magnitude less labeled data, yielding a 10% absolute gain over standard behavior cloning. On a real-world WidowX platform, TAP retains 25% success under camera perturbations where internet-scale baselines collapse to 0%, demonstrating that task-agnostic pretraining produces robust, transferable physical representations and offers a scalable path forward for Embodied AI.
Key Contributions
Decomposition Hypothesis
We propose the Task-Agnostic Pretraining (TAP) framework, which fundamentally decouples the learning of physical affordances ("how to move") from semantic task understanding ("what to do") using self-supervised Inverse Dynamics.
Mitigating the Data Wall
TAP matches or exceeds the performance of foundational VLA models trained on over 1 million expert trajectories by leveraging merely 30 hours of autonomous play and a minimal set of expert data (e.g., 200 real-world demonstrations).
Real-World Robustness
Our method demonstrates exceptional resilience to real-world distribution shifts, retaining up to 65% success under severe background shifts and camera perturbations where internet-scale baselines catastrophically collapse to 0%.
Methodology
Our framework consists of two stages. In Stage 1 (Task-Agnostic Pretraining), the model learns robust physical affordances and motor control without human supervision by predicting the action required to transition between past and future visual frames. In Stage 2 (Task-Specific Alignment), the pretrained model is finetuned on a highly limited set of language-annotated expert demonstrations to align these physical priors with high-level semantic instructions.
Figure 1: Overview of the Task-Agnostic Pretraining (TAP) framework. The pipeline begins by harvesting cheap, unlabeled interaction data from autonomous robot play and repurposed datasets. This fuels Stage 1 pretraining via a self-supervised Inverse Dynamics objective to learn physical affordances ("how to move"), followed by a lightweight Stage 2 finetuning to align these motor priors with semantic language instructions ("what to do").
Quantitative Results
SIMPLER Benchmark Performance
We report task-specific success rates for intermediate sub-goals (Part.) and full task completion (Ent.). Models were fine-tuned using the exact same subset of Stage 2 expert data as our TAP model. Our task-agnostic pretraining significantly boosts physical grounding, yielding a 10% absolute gain over standard behavior cloning and matching models trained on 1M+ trajectories.
| Type | Model Name | Spoon on cloth | Carrot on plate | Stack Blocks | Eggplant in Basket | Avg-Partial | Avg-Entire | Avg-All | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Part. | Ent. | Part. | Ent. | Part. | Ent. | Part. | Ent. | |||||
| Reference | RT-1-X | 4.2% | 0.0% | 16.7% | 0.0% | 0.0% | 0.0% | 3.3% | 0.0% | 6.05% | 0.00% | 3.03% |
| OpenVLA | 4.1% | 0.0% | 33.0% | 0.0% | 12.5% | 0.0% | 8.3% | 4.1% | 14.48% | 1.03% | 7.75% | |
| Nora | 37.5% | 16.7% | 48.0% | 0.0% | 41.7% | 12.5% | 4.17% | 0.0% | 32.84% | 7.29% | 20.06% | |
| Octo | 50.0% | 33.0% | 50.0% | 25.0% | 29.2% | 0.0% | 40.0% | 23.3% | 42.30% | 20.33% | 31.31% | |
| Baseline | Standard BC | 41.7% | 33.3% | 48.0% | 8.0% | 37.5% | 16.7% | 0.0% | 0.0% | 31.79% | 14.50% | 23.15% |
| Ours | TAP-8k episodes | 50.0% | 37.5% | 37.5% | 8.3% | 58.3% | 4.2% | 0.0% | 0.0% | 36.45% | 12.50% | 24.47% |
| TAP-14k episodes | 41.7% | 33.3% | 50.0% | 16.7% | 83.3% | 12.5% | 4.2% | 0.0% | 44.80% | 15.62% | 30.21% | |
| TAP-20k episodes | 66.7% | 58.3% | 50.0% | 0.0% | 58.3% | 16.7% | 8.3% | 8.3% | 45.82% | 20.82% | 33.32% | |
Real-World Robustness
Models are trained on only 200 expert demonstrations. Our TAP model is pretrained on 30 hours of autonomous self-exploration. TAP demonstrates remarkable resilience, surpassing the internet-scale NORA baseline in dynamic tasks with clutter ("Visual Distractors") and consistently outperforming all baselines under severe visual perturbations.
| Evaluation Scenario | Task: Put the carrot on the plate | Task: Push the pumpkin to the left | ||||
|---|---|---|---|---|---|---|
| From scratch | TAP (Ours) | NORA (SOTA) | From scratch | TAP (Ours) | NORA (SOTA) | |
| Standard Setup | 20% | 40% | 65% | 55% | 75% | 85% |
| Initial State Perturbation | 20% | 30% | 65% | 45% | 75% | 80% |
| Visual Distractors | 5% | 30% | 40% | 5% | 65% | 60% |
| Background Texture Shift | 0% | 25% | 10% | 0% | 65% | 55% |
| Viewpoint Variation | 0% | 15% | 0% | 0% | 25% | 0% |
| Average | 9% | 28% | 36% | 21% | 61% | 56% |
Case Studies & Qualitative Analysis
Visualizing Learned Physical Priors (Grad-CAM)
To verify that task-agnostic data instills meaningful physical understanding, we visualize Grad-CAM attention maps.
Without any text prompt, the Stage 1 pretrained model automatically concentrates on the robot gripper and interactive objects (the carrot or pumpkin), suppressing background noise. Once language instructions are introduced in Stage 2, attention strictly collapses onto the specific agent of action (the gripper) to ensure precise execution. This confirms our hypothesis that Stage 1 builds a broad space of physical affordances, while Stage 2 acts as a semantic filter.

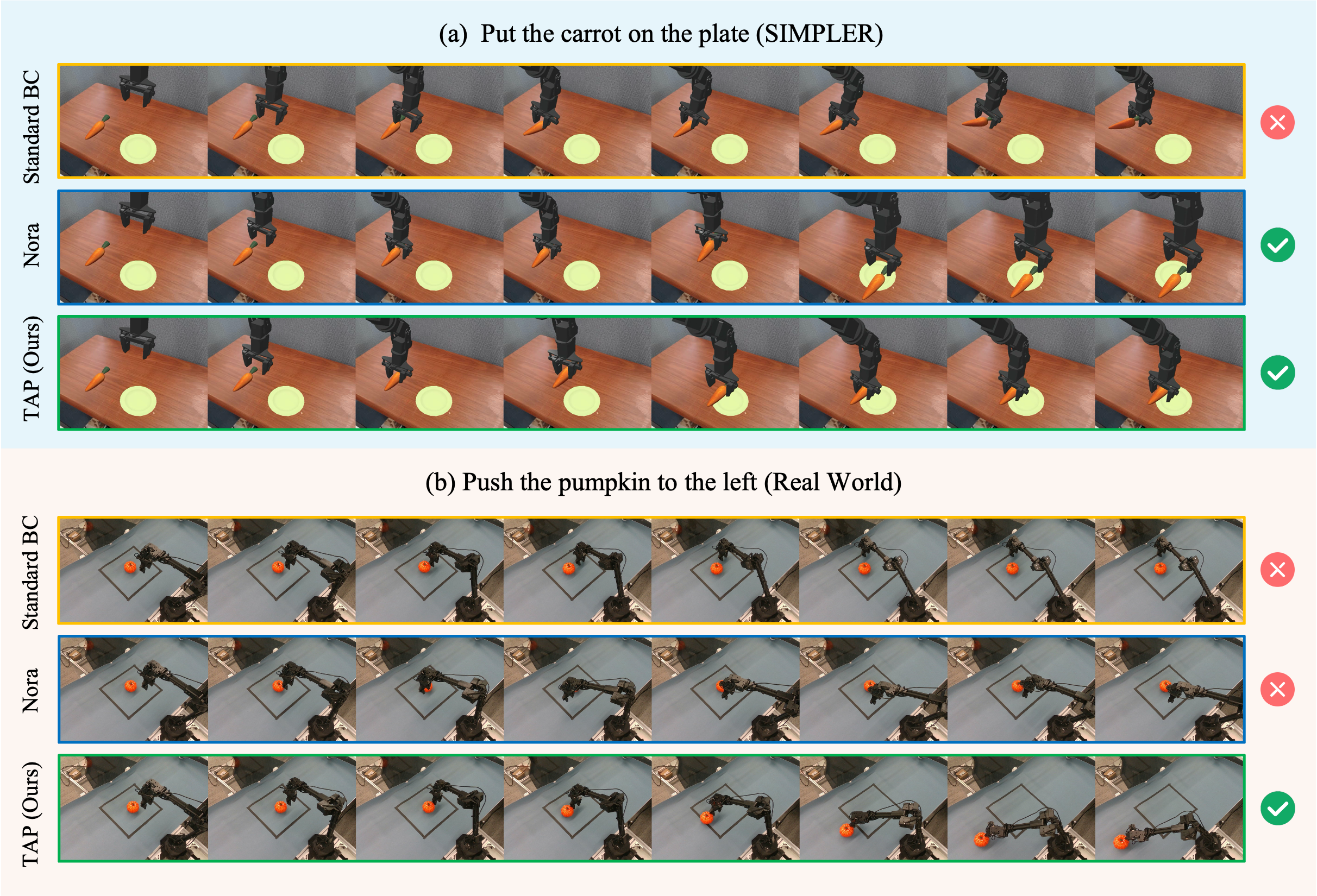
Overcoming Unseen Background Shifts
While standard baselines suffer from severe visual grounding failures when encountering novel table textures (e.g., NORA misjudges the pumpkin's location and pushes empty space), TAP accurately isolates the manipulable object, showcasing superior 3D spatial reasoning derived from robust, task-agnostic physical priors.
Poster

BibTeX
@article{tap2025,
title = {TAP: Task-Agnostic Pretraining for Data-Efficient Vision-Language-Action Models},
author = {First Author and Second Author and Third Author},
journal = {arXiv preprint arXiv:ARXIV_ID},
year = {2025},
url = {https://YOUR_DOMAIN.github.io/TAP}
}